Apache Spark Discretized Streams (DStreams) with Pyspark
What is Streaming ?
Try to imagine this; in every single second , nearly 9,000 tweets are sent , 1000 photos are uploaded on instagram, over 2,000,000 emails are sent and again nearly 80,000 searches are performed according to Internet Live Stats.
So many data is generated without stopping from many sources and sent to another sources simultaneously in small packages.
Many applications also generate consistently-updated data like sensors used in robotics, vehicles and many other industrial and electronical devices stream data for monitoring the progress and the performance.
That’s why great numbers of generated data in every second have to be processed and analyzed rapidly in real time which means “Streaming”.
DStreams
Spark DStream (Discretized Stream) is the basic concept of Spark Streaming. DStream is a continuous stream of data.The data stream receives input from different kind of sources like Kafka, Kinesis, Flume, TCP sockets or it recieves input after some processing stage on the original data. DStream is a also continuous stream of RDD (Resilient Distributed Datasets). Every RDD in DStream contains data from the certain time interval. Spark Streaming has also fault-tolerance feature for DStreams as like for RDDs.
Let’s look at our DStream example
from pyspark.context import SparkContext
from pyspark.streaming import StreamingContext
from time import sleepsc = SparkContext(appName="DStream_QueueStream")
ssc = StreamingContext(sc, 2)
rddQueue = []
for i in range(3):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 21)],10)]inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x: (x % 10, 1))
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)
reducedStream.pprint()ssc.start()
#sleep(6)
ssc.stop(stopSparkContext=True, stopGraceFully=True)
As you can see at first, we have created a Spark context and then the streaming context which has a “2" inside, meaning that we want to read streaming data in every 2 seconds.
We have created an input data, which is a list of integers from 1 to 20. With Spark Context parallelize we slice the data into 10 partition and we repeat it 3 times with a for loop. Finally we have an input stream which is going to be read in every 2 seconds. Let’s look at the structure of our input data in which we wrap in a Spark streaming context as queueStream.
rddQueue[ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:262,
ParallelCollectionRDD[1] at readRDDFromFile at PythonRDD.scala:262,
ParallelCollectionRDD[2] at readRDDFromFile at PythonRDD.scala:262]rddQueue[0].glom().collect()[[1, 2],
[3, 4],
[5, 6],
[7, 8],
[9, 10],
[11, 12],
[13, 14],
[15, 16],
[17, 18],
[19, 20]]
After some transformations like map and reduce functions, we have an action, pprint, which will start the computation. Finally streaming starts with ssc.start() and after 6 seconds sleep time we terminated data streaming with ssc.stop() command.
Here is the output data of our DStream example:
-------------------------------------------
Time: 2021-01-01 22:57:16
-------------------------------------------
(8, 2)
(0, 2)
(1, 2)
(9, 2)
(2, 2)
(3, 2)
(4, 2)
(5, 2)
(6, 2)
(7, 2)
-------------------------------------------
Time: 2021-01-01 22:57:18
-------------------------------------------
(8, 2)
(0, 2)
(1, 2)
(9, 2)
(2, 2)
(3, 2)
(4, 2)
(5, 2)
(6, 2)
(7, 2)
-------------------------------------------
Time: 2021-01-01 22:57:20
-------------------------------------------
(8, 2)
(0, 2)
(1, 2)
(9, 2)
(2, 2)
(3, 2)
(4, 2)
(5, 2)
(6, 2)
(7, 2)
Now let’s try to demonstrate it with another example
from pyspark.context import SparkContext
from pyspark.streaming import StreamingContext
from time import sleepsc=SparkContext("local[*]","StreamingExample")
ssc=StreamingContext(sc,5)
lines=ssc.textFileStream(r'home/data')words=lines.flatMap(lambda x:x.split(" "))
mapped_words=words.map(lambda x:(x,1))
reduced_words=mapped_words.reduceByKey(lambda x,y:x+y)
sorted_words=reduced_words.map(lambda x:(x[1],x[0])).transform(lambda x:x.sortByKey(False))
sorted_words.pprint()ssc.start()
sleep(20)
ssc.stop(stopSparkContext=True, stopGraceFully=True)-------------------------------------------
Time: 2021-01-02 00:46:20
-------------------------------------------
(4, 'and')
(4, 'can')
(3, 'data')
(3, 'be')
(2, 'of')
(2, 'like')
(2, 'algorithms')
(2, 'processing')
(2, 'Spark')
(2, 'live')
(2, 'processed')
(1, 'an')
(1, 'high-throughput,')
(1, 'using')
...
-------------------------------------------
Time: 2021-01-02 00:46:25
-------------------------------------------
In the second example we have a text file as an input data, which has a small paragraph about Spark streaming. After some transformations on the data (an example of famous word count☺), we started streaming which will read in every 5 seconds. Most important part is that the input data should be sent just after we started the streaming with ssc.start() command. Last modification time of the text file has to be after the time of the beginning of the stream.
Windowed Operations
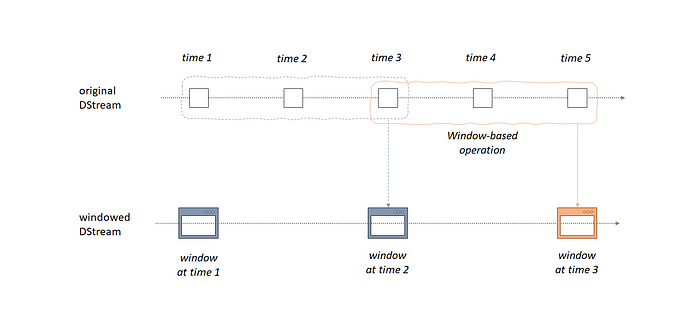
Finally I would like to mention about windowed operations of DStreams. It offers to apply transformations over a sliding window of data.Essentially, any Spark window operation needs two main parameters;
- Window duration which defines the duration of the window
- Sliding duration which defines the duration at which the window operation is performed
Another important thing about these 2 parameters is that they have to be multiples of the batch interval of the source DStream.
Let’s try to figure out windowed operation with the example below
from pyspark.context import SparkContext
from pyspark.streaming import StreamingContextsc = SparkContext(master=”local[*]”, appName=”WindowWordcount”)
ssc = StreamingContext(sc, 1)
ssc.checkpoint(r”C:\Users\SERCAN\Desktop\databases\checkpoint”)lines = ssc.socketTextStream(“localhost”, 9999)
words = lines.flatMap(lambda line: line.split(“ “))
pairs = words.map(lambda word: (word, 1))
pairs.window(10, 5).pprint()ssc.start()
-------------------------------------------
Time: 2021-01-02 01:53:28
-------------------------------------------
-------------------------------------------
Time: 2021-01-02 01:53:33
-------------------------------------------
('foo', 1)
-------------------------------------------
Time: 2021-01-02 01:53:38
-------------------------------------------
('foo', 1)
('bar', 1)
-------------------------------------------
Time: 2021-01-02 01:53:43
-------------------------------------------
('bar', 1)
('baz', 1)
-------------------------------------------
Time: 2021-01-02 01:53:48
-------------------------------------------
('baz', 1)
-------------------------------------------
Time: 2021-01-02 01:53:53
-------------------------------------------
In the third example, i used socket for supplying input data from command terminal. The input times are;
01:53:30 — foo
01:53:35 — bar
01:53:40 — baz
As you can see from the example in first 10 seconds window (:28-:38) we can only see “foo,1” but then in the second window we still have “foo” but also we now get “bar,1” for also :33-:43 window. In the third window this time “foo” dissappears because its window is closed but now we have “baz,1” from a new window (:38–:48) and also still have “bar” for :33-:43 window. Finally for the forth window now we only have “baz” because its window time ends at :48.
Conclusion
In this article, I have tried to introduce DStreams which is an unstructured part of Spark Streaming. DStream represents a continuous stream of data. Like RDD in Spark, DStreams are also getting old-fashioned but it is always good to know basics or start from the basics.
I hope you will find this article helpful. In the next article, I will talk about the Structured part of Spark Streaming which is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine.
I will be happy to hear any comments or questions from you. May the data be with you!
Comments
Post a Comment