Get your team together – the domain experts and the technical experts – and set them about creating a document that tracks your team’s language. This is the living document of all the terminology your team uses – along with all its definitions. This is known as the Glossary:  From now on, use only the term definitions listed here in your stories both in person AND in your source code. Be explicit about how you use your language! I’ve been on many projects where the sloppy usage of a term from project inception led to the usage of that term in the code – codifying that messy, slippery term throughout the life of the project. The purpose of the Ubiquitous Language is to get the whole team on the same page – what each thing means, and bridge the gap between the jargon used on the development team and the customers.
From now on, use only the term definitions listed here in your stories both in person AND in your source code. Be explicit about how you use your language! I’ve been on many projects where the sloppy usage of a term from project inception led to the usage of that term in the code – codifying that messy, slippery term throughout the life of the project. The purpose of the Ubiquitous Language is to get the whole team on the same page – what each thing means, and bridge the gap between the jargon used on the development team and the customers. 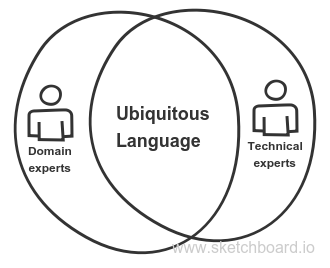 Your Glossary is a living document. It is meant to be living – either on a continually updated Google Doc or a wiki page. It should be visible for all to see – you should print it out and post it on the walls!
Your Glossary is a living document. It is meant to be living – either on a continually updated Google Doc or a wiki page. It should be visible for all to see – you should print it out and post it on the walls!
Refactoring your team to use the right terms
A great time and place to start using this new Ubiquitious Language is in your everyday conversations with your domain experts, or with the technical team. Let’s listen in on a planning meeting with the product owner:
You: So when a User logs into the app and broadcasts that they’re ready to drive… PO: You mean Driver. When a Driver logs in. You: Right. Good catch.
The little correction seems a little silly (after all, you both know only Drivers use the broadcast feature of the app), but the laser focus on using the right words means that your team is always on the same page when talking about things. As your team starts using the defined terms in the Glossary, the same words start to slip off your tongues, making working together easier than ever. Later that afternoon, your teammate taps you on the shoulder:
Teammate: I’m about to start working on the checkout flow. I suggest we rename the Discount class to Coupon. You: Great idea. That way, we aren’t tripped up by the naming mismatches in the future.
Congratulations! Your team is making its first steps to Ubiquitous Language nirvana: your code needs to reflect your domain language.
Teammate: I do have a question about the coupon, though. Do you think it’s applied to the BookingAmount, or is it added? PO: [Overhearing conversation] You had it right. It’s applied.
You and your teammate then go and update the glossary, scribbling an addendum on the wall (or updating your wiki):  Future teammates will thank you for your precision with your terms.
Future teammates will thank you for your precision with your terms.
Refactoring your code to use the right terms
Your teammate and you then walk over to her desk; as a pair you proceed to refactor the existing account code. We’ll use Ruby for the sake of this example. In the beginning, the Checkout code looks like this. A pretty straightforward implementation of the parts of the checkout flow that apply a coupon. https://gist.github.com/andrewhao/4783e3636fb1e47adfa195b749986733#file-pass_1-rb
You take a first pass and rename the Discount class to Coupon. https://gist.github.com/andrewhao/4783e3636fb1e47adfa195b749986733#file-pass_2-rb
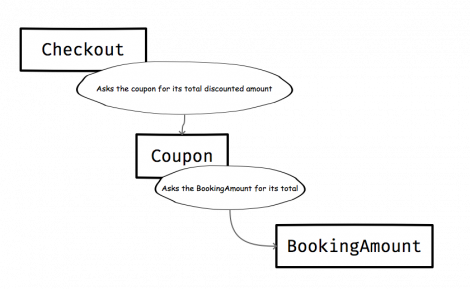
Now there’s something funny here – your domain language suggests that a Coupon is applied to a BookingAmount. You pause, because the code reads the opposite – “A Coupon calculates its amount for a BookingAmount”.
You: How about we also refactor the calculate_amount_for method to reflect the language a little better? Teammate: Yeah. It sounds like the action occurs the other way – the BookingAmount is responsible for applying a Coupon to itself.In your next refactoring pass, you move the calculate_amount_for method into the BookingAmount, renaming it applied_coupon_amount: https://gist.github.com/andrewhao/4783e3636fb1e47adfa195b749986733#file-pass_3-rb
Finally, you change your Checkout implementation to match: https://gist.github.com/andrewhao/4783e3636fb1e47adfa195b749986733#file-pass_4-rb Here’s the new diagram: 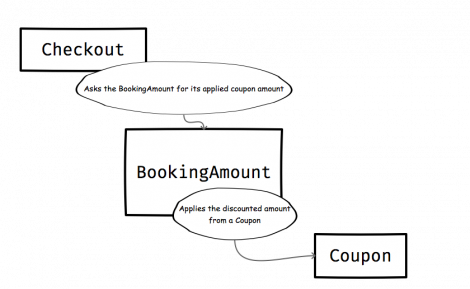 Remember: we wanted our code to match the domain language: “A Coupon is applied to a BookingAmount“. When you read the implementation in plain English, it reads:
Remember: we wanted our code to match the domain language: “A Coupon is applied to a BookingAmount“. When you read the implementation in plain English, it reads:
The Checkout‘s total amount is its BookingAmount minus its applied Coupon amount.
Phew! Designing a strong Ubiquitous Language was hard work! In fact, you had spent a serious amount of time debating and clarifying with your domain experts:
- Is a Coupon applied to a BookingAmount, or is it added to one?
- Should we call the monetary value of a Coupon its amount, or cost?
- Is the pre-tax, pre-discount amount in the BookingAmount called a price, or a cost?
Whatever you agreed on, that’s what you changed your code to reflect.
In closing…
In this brief time we had together,
- We discussed why names are important – especially in a complex endeavour like software development.
- We covered why it’s important to arrive at a shared understanding, together as a team, using the same words and vocabulary.
- We discovered how to build and integrate a Glossary into the daily rhythm of our team.
- We refactored the code twice – illustrating how to get code in line with the domain language.
Comments
Post a Comment